- Syllabus
- 1 Introduction
- 2 Data in Biology
- 3 Preliminaries
- 4 R Programming
- 4.1 Before you begin
- 4.2 Introduction
- 4.3 R Syntax Basics
- 4.4 Basic Types of Values
- 4.5 Data Structures
- 4.6 Logical Tests and Comparators
- 4.7 Functions
- 4.8 Iteration
- 4.9 Installing Packages
- 4.10 Saving and Loading R Data
- 4.11 Troubleshooting and Debugging
- 4.12 Coding Style and Conventions
- 4.12.1 Is my code correct?
- 4.12.2 Does my code follow the DRY principle?
- 4.12.3 Did I choose concise but descriptive variable and function names?
- 4.12.4 Did I use indentation and naming conventions consistently throughout my code?
- 4.12.5 Did I write comments, especially when what the code does is not obvious?
- 4.12.6 How easy would it be for someone else to understand my code?
- 4.12.7 Is my code easy to maintain/change?
- 4.12.8 The
stylerpackage
- 5 Data Wrangling
- 6 Data Science
- 7 Data Visualization
- 8 Biology & Bioinformatics
- 8.1 R in Biology
- 8.2 Biological Data Overview
- 8.3 Bioconductor
- 8.4 Microarrays
- 8.5 High Throughput Sequencing
- 8.6 Gene Identifiers
- 8.7 Gene Expression
- 8.7.1 Gene Expression Data in Bioconductor
- 8.7.2 Differential Expression Analysis
- 8.7.3 Microarray Gene Expression Data
- 8.7.4 Differential Expression: Microarrays (limma)
- 8.7.5 RNASeq
- 8.7.6 RNASeq Gene Expression Data
- 8.7.7 Filtering Counts
- 8.7.8 Count Distributions
- 8.7.9 Differential Expression: RNASeq
- 8.8 Gene Set Enrichment Analysis
- 8.9 Biological Networks .
- 9 EngineeRing
- 10 RShiny
- 11 Communicating with R
- 12 Contribution Guide
- Assignments
- Assignment Format
- Starting an Assignment
- Assignment 1
- Assignment 2
- Assignment 3
- Problem Statement
- Learning Objectives
- Skill List
- Background on Microarrays
- Background on Principal Component Analysis
- Marisa et al. Gene Expression Classification of Colon Cancer into Molecular Subtypes: Characterization, Validation, and Prognostic Value. PLoS Medicine, May 2013. PMID: 23700391
- Scaling data using R
scale() - Proportion of variance explained
- Plotting and visualization of PCA
- Hierarchical Clustering and Heatmaps
- References
- Assignment 4
- Assignment 5
- Problem Statement
- Learning Objectives
- Skill List
- DESeq2 Background
- Generating a counts matrix
- Prefiltering Counts matrix
- Median-of-ratios normalization
- DESeq2 preparation
- O’Meara et al. Transcriptional Reversion of Cardiac Myocyte Fate During Mammalian Cardiac Regeneration. Circ Res. Feb 2015. PMID: 25477501l
- 1. Reading and subsetting the data from verse_counts.tsv and sample_metadata.csv
- 2. Running DESeq2
- 3. Annotating results to construct a labeled volcano plot
- 4. Diagnostic plot of the raw p-values for all genes
- 5. Plotting the LogFoldChanges for differentially expressed genes
- The choice of FDR cutoff depends on cost
- 6. Plotting the normalized counts of differentially expressed genes
- 7. Volcano Plot to visualize differential expression results
- 8. Running fgsea vignette
- 9. Plotting the top ten positive NES and top ten negative NES pathways
- References
- Assignment 6
- Assignment 7
- Appendix
- A Class Outlines
2.2 Biology as a Mature Data Science
The completion of the first draft human genome ushered in a revolution in how we understand ourselves as humans, from our evolutionary history, our ancestry, our traits, and our health. It provided fundamentally new and empirical tools and approaches to human genetic and biomedical research, and the technologies and techniques that were developed in the completion of the draft sequence formed the foundation for genetic research in non-human systems as well.
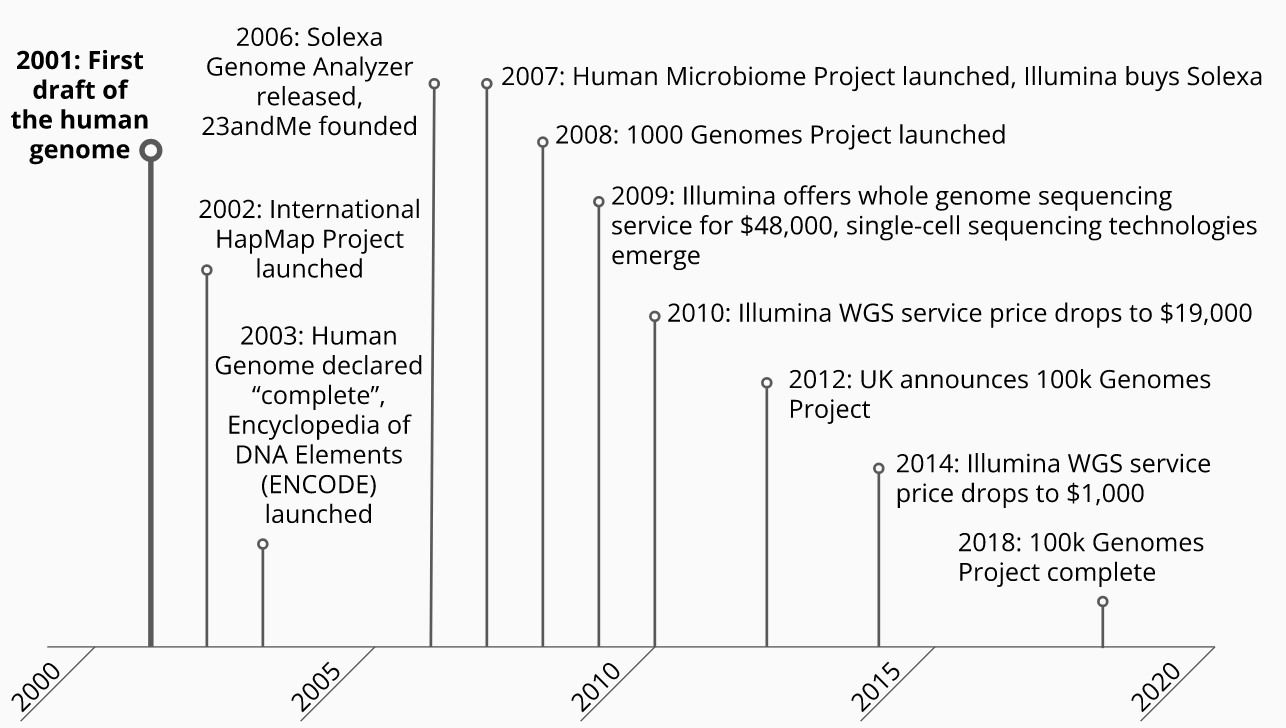
Biological Data Timeline - Human Genome Era
While the focus of the human genome project was on determining the DNA sequence of the human genome, this sequence and the technologies used to ascertain it provide us with opportunities to learn many other properties of genomes and biological systems by analyzing the data with different approaches. For example, knowing the complete sequence of a genome also provides information on the number of genes it contains, how repetitive the sequence is, and when combined with genetic sequences of other individuals or organisms, how closely related genes or even organisms as a whole are. Thanks to the central dogma of molecular biology, the gene sequences also give us information about the intermediate RNA molecule and resultant proteins encoded by a genome, creating opportunities for new ideas, hypotheses, experiments, and even new data-generating assays and approaches. These advances are causing exponential growth of different types of biological data and its volume, necessitating ever more powerful and sophisticated computational resources and analytical methods with no signs of slowing.
The biochemical instruments used to produce these data are continually improving the precision, accuracy, throughput, and cost of their output and operations.
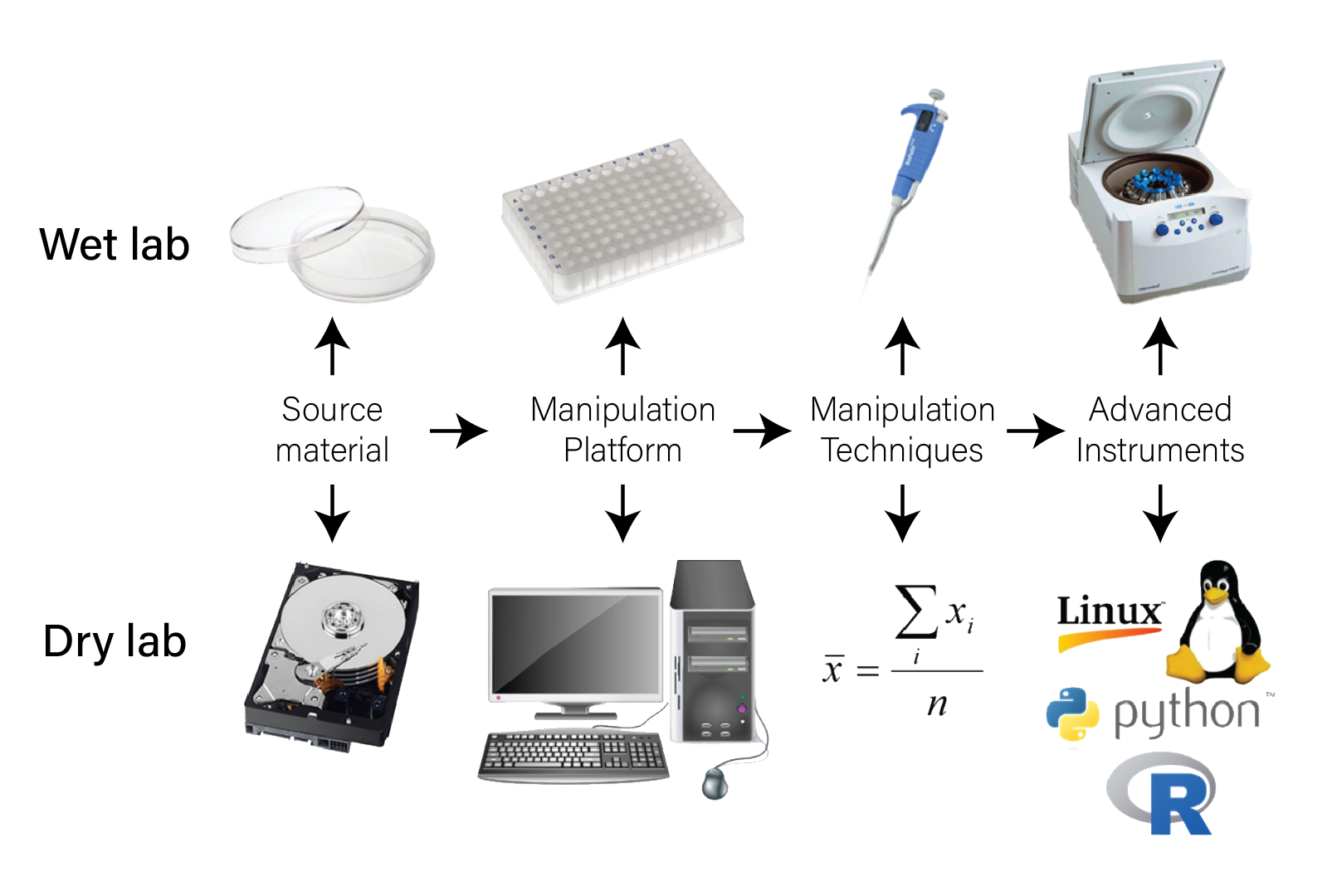
The Biologist’s Tools